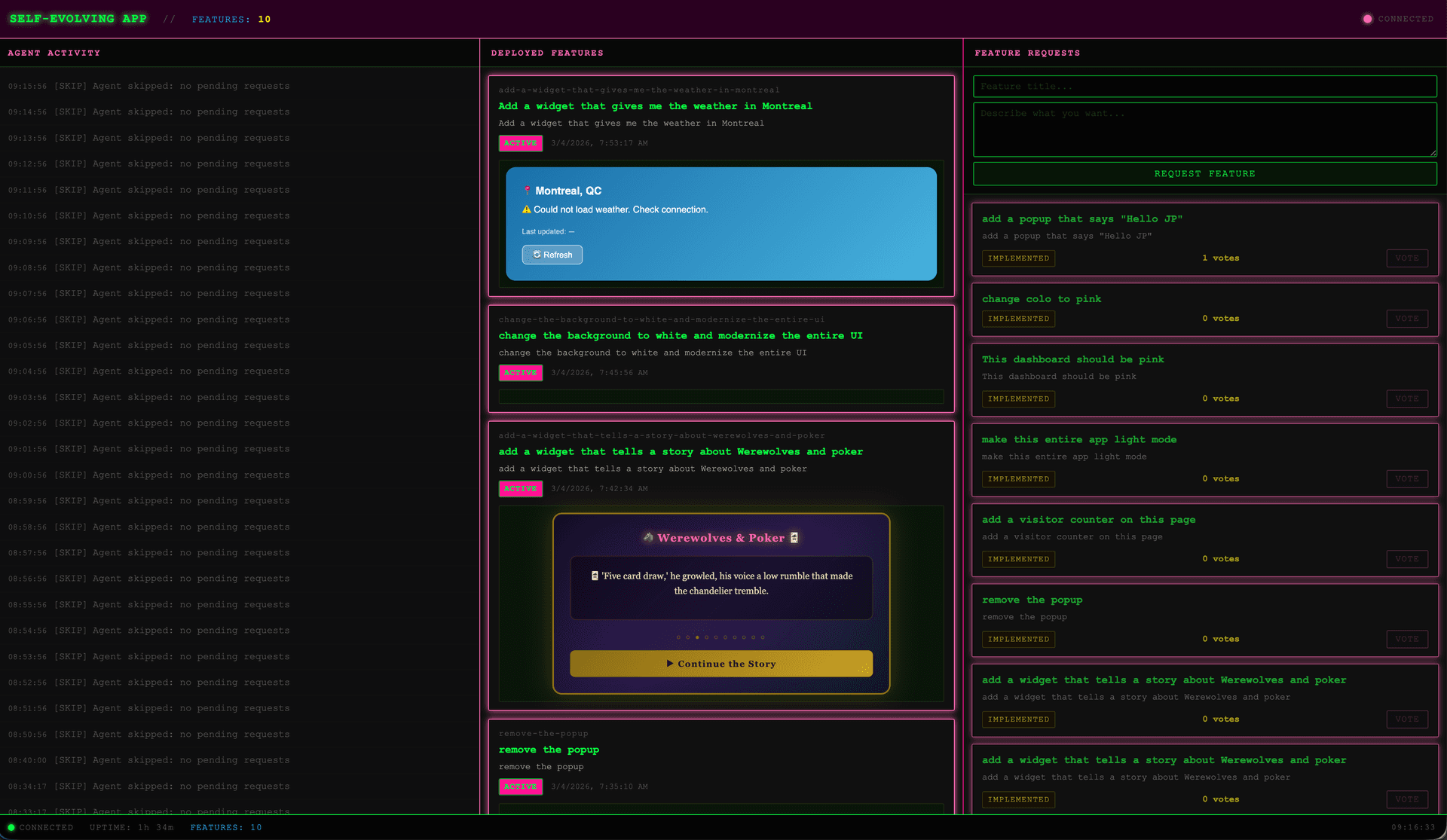
I Built a Server That Rewrites Itself While Running
A Node.js server where visitors vote on features they want, an AI agent writes the code, and the server deploys it to itself. Live. No restart, no build step, no deployment pipeline.
Here’s the setup: a Node.js server where visitors vote on features they want, an AI agent writes the code, and the server deploys it to itself. Live. No restart, no build step, no deployment pipeline.
The backend is the product manager, the developer, and the QA team. About 700 lines of JavaScript running in a single process.
I know how that sounds. Allow me to explain why it actually works, what breaks, and what it accidentally reveals about where software is headed.
The Loop
Every 60 seconds, a cycle kicks off.
An Observer agent queries a SQLite database for user-submitted feature requests, sorted by vote count. It picks the top-voted pending request and hands that context to a Developer agent. The Developer agent calls the Claude API with a system prompt that’s almost comically strict: “Write a Node.js module that exports mount(routes, db). Return only valid JavaScript. No markdown.”
Before the generated code touches disk, a sandbox validator runs node --check on it and scans for blocked patterns. child_process, eval, fs.writeFile, require('net'), anything that could let generated code escape its sandbox. If it fails, the request is flagged, and the loop continues.
If it passes, the file lands in features/werewolves-poker.js (or whatever the feature slug is). A file watcher picks up the change, busts the module cache, and calls mount() on the fresh module. New HTTP routes register on the live server. A Server-Sent Event fires to every connected browser. The dashboard updates in real time.
The whole thing takes about 4 seconds from “validator passes” to “new feature card appears in every user’s browser.”
The require.cache Trick
This is the mechanical heart of the experiment, and it depends on a quirk of Node.js that most developers never think about.
Every require() call in Node is memoized. When you require('./features/poker.js'), Node reads the file, compiles it, caches the result in require.cache, and never reads that file again for the lifetime of the process. This is why your Node server doesn’t re-parse every module on every request. It’s a performance feature.
But it’s also a lever.
// The hot-reload mechanism in ~10 lines
const modulePath = require.resolve(./features/${slug}.js);
delete require.cache[modulePath];
const feature = require(modulePath);
feature.mount(router, db);
Delete the cache entry. Require it again. Node reads the new file from disk, compiles fresh bytecode, and returns the updated module. chokidar watches the features/ directory and triggers this on every file change. The old module’s routes get replaced. The new module’s routes go live.
This isn’t a new technique. Tools like nodemon and various hot-module-replacement setups employ similar tricks. But there’s something different about watching an AI agent trigger it. You’re not editing a file in VS Code and saving. A language model is writing JavaScript that your server compiles and serves, and nobody human touched it between “Claude generated this” and “users are hitting these endpoints.”
That gap is where the interesting questions live.
The Widget Contract
Here’s the part that surprised me most during development. The agent doesn’t just write backend logic. It writes UI.
Every feature module can expose a GET /api/features/<id>/widget endpoint that returns an HTML fragment. The frontend fetches it and injects it into the dashboard via innerHTML. This means a single Claude API call can produce a feature that has routes, database queries, and a visual interface, all in one file.
There’s a catch with innerHTML, though. Browsers won’t execute <script> tags injected this way. It’s a security feature. The workaround: after injection, you walk the DOM, find any <script> elements, create new <script> elements with the same content, and append them. <style> tags work fine via innerHTML and apply CSS to the whole page immediately.
// Re-activating scripts after innerHTML injection container.querySelectorAll("script").forEach((oldScript) => { const newScript = document.createElement("script"); newScript.textContent = oldScript.textContent; oldScript.replaceWith(newScript); });
The widget contract turns what could be a headless API experiment into something visceral. You vote for a feature. Seconds later, a card appears on your screen with working UI. The feedback loop is tight enough to feel like magic, even when you built the thing and know exactly what’s happening underneath.
SSE Keeps Everyone in Sync
Server-Sent Events are the glue. When a new feature deploys, the server broadcasts an event to every connected browser. The frontend listens, and either fetches the new widget or updates the feature list.
SSE is an underappreciated protocol for this kind of thing. It’s simpler than WebSockets (unidirectional, auto-reconnects, works through most proxies), and for a “server pushes updates to browsers” pattern, you don’t need the bidirectional channel that WebSockets provide. One EventSource connection per client, one res.write() per event on the server. The MDN documentation on Server-Sent Events covers the protocol well if you haven’t used it before.
The entire architecture, HTTP server, file watcher, agent loop, SSE hub, and SQLite run in a single Node.js process. No microservices. No message queue. No orchestration layer. The simplicity is the point.
What the Validator Actually Catches
The sandbox validator is doing real work here, and it’s the difference between a fun demo and a security incident.
Before any generated code gets written to disk, it runs through two checks. First, node --check verifies that the syntax is valid JavaScript. This catches malformed model output, missing brackets, hallucinated syntax, and incomplete functions. It happens more often than you’d expect, maybe 1 in 8 generations in my testing.
Second, a pattern scanner looks for dangerous APIs:
- child_process (shell access)
- eval and Function() (arbitrary code execution)
- fs.writeFile and fs.unlink (filesystem writes outside the sandbox)
- require('net') and require('http') (outbound connections)
- process.env (credential access)
If any pattern matches, the code never touches disk. The request gets logged as failed, and the loop moves to the next highest-voted feature.
Is this production-grade security? No. A sufficiently creative prompt injection could probably sneak past string matching. But for a demo, it draws a useful line: the generated code can read from the database and register HTTP routes, and that’s about it.
What This Proves (and What It Doesn’t)
It proves the mechanical parts work. Hot-reloading AI-generated modules into a running Node server is not theoretically possible. It works. Today. In about 700 lines of code. The gap between “AI writes code” and “code is running in production” can be collapsed to single-digit seconds with surprisingly little infrastructure.
It proves that the feedback loop changes the dynamic. When users see their request go from vote to running feature in under a minute, something changes in how they interact with the system. They stop submitting vague requests (“make it better”) and start submitting specific ones (“add a dark mode toggle that persists in localStorage”). The tight feedback loop trains the users.
It does not prove this is how we should build software. There’s no test suite. There’s no code review. There’s no rollback mechanism beyond “delete the file and the watcher removes the routes.” The feature modules can stomp on each other’s routes. The generated code quality varies wildly, sometimes Claude produces clean, well-structured modules; sometimes it produces something that technically works, but you’d never want to maintain.
And the voting system is doing a lot of quiet work that’s easy to overlook. IP-deduplicated votes in a SQLite table sounds trivial, but it’s acting as a crude prioritization layer. The crowd is, in effect, writing the product roadmap. That works for a demo with 20 concurrent users. It breaks down fast when you need to consider technical debt, security implications, or architectural coherence.
The Genuinely Interesting Bit
Here’s what I keep coming back to. The interesting thing about this experiment isn’t the hot-reload trick, the SSE broadcasts, or even the Claude API integration. Those are just plumbing.
The interesting thing is that the distance between “someone has an idea” and “that idea is running as code” is now measurable in seconds. And most of what fills that distance in real software organizations isn’t writing code. It’s a process. Reviews, approvals, scheduling, prioritization meetings, deployment windows, staging environments, and rollback plans.
This experiment deletes all of that. And the result is… kind of exciting and kind of terrifying?
The features that get generated work. Mostly. They serve real HTTP responses. They render real UI. But they accumulate in a directory with no organizing principle, no shared state management, no consistent error handling. After a dozen features, the features/ directory starts to feel like a codebase that 12 different developers worked on without ever talking to each other. Because that’s exactly what happened, except that the 12 developers were all using the same language model, responding to 12 different prompts.
This is the part that maps onto real codebases adopting AI-assisted development. The generation is fast. The coherence is hard.
Where This Actually Points
I don’t think the future looks like servers rewriting themselves in production. But I do think the future looks like the gap between intent and running code getting radically shorter.
The pieces already exist. AI models that can produce working code from natural language descriptions. Validation systems that can check the generated output before it runs. Hot-reload mechanisms that can integrate new code without restarts. Real-time protocols that can push changes to every connected client.
What’s missing is the connective tissue. The part that ensures generated feature #47 doesn’t break features #1 through #46. The part that retains architectural coherence when code is being written by a model that has no memory of what it wrote yesterday. The part that CI/CD pipelines were built to handle: making sure new code doesn’t break the old code.
The experiment is 700 lines because it skips all of that. Real systems can’t.
But here’s the thought I can’t shake. I built this in an hour. The agent loop, the validator, the hot-reload, the SSE hub, and the widget contract. One hour. And it works well enough that people who use it genuinely forget there’s no human developer on the other end.
If an hour project can close that gap for a toy app, what does a well-funded team with proper testing infrastructure, a real CI/CD pipeline, and architectural guardrails close it for?
That’s the question worth sitting with.
Related experiments
What Snake Games Have Taught Us About Shipping with AI Agents
Five months of Loop Lab Snake builds trace a path from AFK Ralph loops to 100% green PRs and 3x faster CI feedback. Same benchmark, four breakthroughs.
The Sidecar Race: 22 Seconds vs 69 Seconds Inside the Agent Loop
A controlled A/B in chunk-cli: same lint+test gates, sidecar remote validate vs push-per-task CI. Median time to signal 3.1x faster on sidecar; LLM costs relatively flat.
AFK Builds with 100% Green PRs (Chunk Sidecars Inside the Agent Loop)
Five RalphCI Snake game builds with Chunk sidecars in the Review Gate: AFK agent loops, pre-push CI parity, and 100% green pull requests end-to-end.